
Blueprint for Success
Kanister, developed by Kasten and acquired by Veeam, has defined a number of objectives for its data management tool [1]. The focus is on application-centric backup, which, in concrete terms, means the target group is primarily users of specialist applications and not just those who deal with system-related infrastructure. The developers opted for an API-based approach to programming: All addressable tasks are abstracted by a well-defined API, which is also very easy to extend.
ActionSets and Blueprints
Like many other Kubernetes products, Kanister's implementation is based on the operator principle, which made it easy for Veeam to package, deploy, and manage Kanister, providing a range of Kubernetes resource definitions. In total, Kanister comprises three main components: one controller and two custom resources – ActionSets and Blueprints. The workflow is shown in Figure 1:
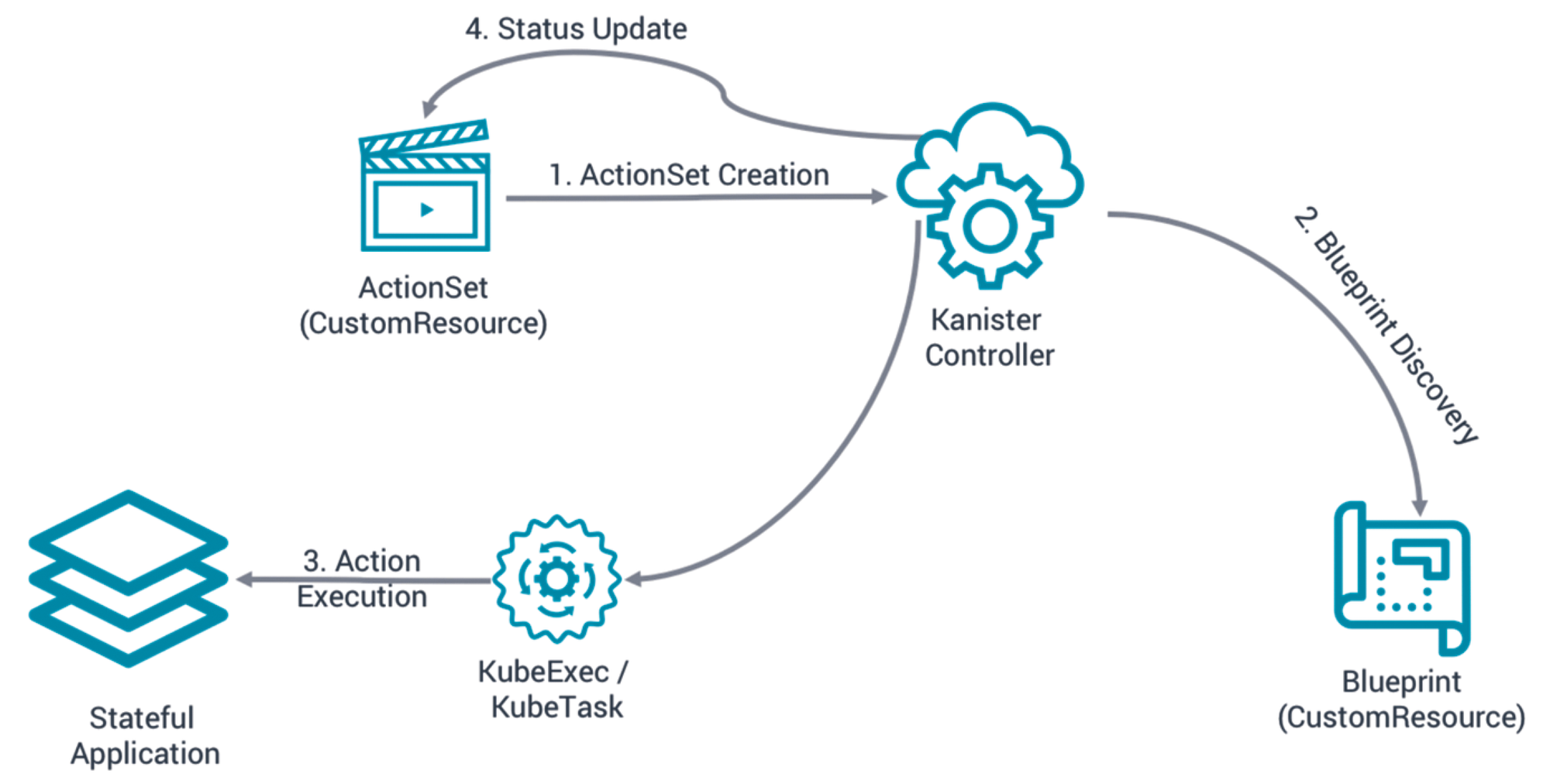
- First, an ActionSet is created. An ActionSet, which like most manifests is declarative, describes a set of
actionsto be executed on Kubernetes resources at runtime. Each action is linked to a Kubernetes object and references a Blueprint with the required information. - The Kanister controller then reads the transferred ActionSet and loads the referenced Blueprints that define commands for execution on Kubernetes resources, such as freezing a database.
- After finding and loading the matching Blueprints, the controller executes the commands from the Blueprints with
KubeExec/KubeTask. - Once all of the actions in the ActionSet have been completed, a status message is generated and saved in the ActionSet.
Simple Workflow Example
As already mentioned, Kanister uses ActionSets, actions, and Blueprints as custom resources in the background. The example application in Listing 1, which will be further refined, shows how Kanister works.
Listing 1: Deployment
cat <<EOF | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: time-logger
spec:
replicas: 1
template:
metadata:
labels:
app: time-logger
spec:
containers:
- name: test-container
image: amazon/aws-cli
command: ["sh", "-c"]
args: ["while true; do for x in $(seq 1200); do date >> /var/log/time.log; sleep 1; done; truncate /var/log/time.log --size 0; done"]
EOFThe deployment has deliberately been kept simple. In the shell, it just writes the current date to a logfile at regular intervals. Now, you can start writing a Blueprint. In many cases, this step is not even necessary because Kanister already provides a large number of Blueprint templates in its GitHub repository for databases such as PostgreSQL, MySQL, MongoDB, ElasticSearch, and many others. Listing 2 is an example of an initial Blueprint.
Listing 2: Blueprint
cat <<EOF | kubectl create -f -
apiVersion: cr.kanister.io/v1alpha1
kind: Blueprint
metadata:
name: time-log-bp
namespace: kanister
actions:
backup:
phases:
- func: KubeExec
name: backupToS3
args:
namespace: "{{ .Deployment.Namespace }}"
pod: "{{ index .Deployment.Pods 0 }}"
container: test-container
command:
- sh
- -c
- echo /var/log/time.log
EOFThe Blueprint contains just one action (backup) that executes a pod (KubeExec) and passes in a command (in the first iteration, the log protocol output). After creating the Blueprint, you can issue a command to make sure it worked:
kubectl --namespace kanister describe Blueprint time-log-bpThe next step is to create an ActionSet. As I already mentioned, you need an ActionSet to execute the actions contained in your Blueprints at runtime. Again, you can use kubectl (Listing 3).
Listing 3: ActionSet
cat <<EOF | kubectl create -f -
apiVersion: cr.kanister.io/v1alpha1
kind: ActionSet
metadata:
generateName: s3backup-
namespace: kanister
spec:
actions:
- name: backup
blueprint: time-log-bp
object:
kind: Deployment
name: time-logger
namespace: default
EOFThen, after running Listing 3, use
kubectl --namespace kanister get actionsets.cr.kanister.io-o yaml
kubectl --namespace kanister get pod -l app=kanister-operator
to query the current status.
Refining the Backup
At this point, you already have a simple Kanister workflow. However, it is not yet very generic. If you want to make the workflow configurable, it would make sense to wrap the configuration settings in a Kubernetes ConfigMap, which can then be read from a Blueprint. The next command stores the data path in the ConfigMap where the backup is to be created. Of course, you will need to adapt the path to suit your own environment:
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: s3-location
namespace: kanister
data:
path: s3://it-admin-bucket/tutorial
EOFThe next step is to extend the Blueprint so that it expects some location input for the ConfigMaps (Listing 4). At this point, you can now create a new ActionSet to reference the ConfigMap just generated and pass it to the Blueprint just defined (Listing 5).
Listing 4: Extending the Blueprint
cat <<EOF | kubectl apply -f -
apiVersion: cr.kanister.io/v1alpha1
kind: Blueprint
metadata:
name: time-log-bp
namespace: kanister
actions:
backup:
configMapNames:
- location
phases:
- func: KubeExec
name: backupToS3
args:
namespace: "{{ .Deployment.Namespace }}"
pod: "{{ index .Deployment.Pods 0 }}"
container: test-container
command:
- sh
- -c
- |
echo /var/log/time.log
echo "{{ .ConfigMaps.location.Data.path }}"
EOFListing 5: Referencing the ConfigMap
cat <<EOF | kubectl create -f -
apiVersion: cr.kanister.io/v1alpha1
kind: ActionSet
metadata:
generateName: s3backup-
namespace: kanister
spec:
actions:
- name: backup
blueprint: time-log-bp
object:
kind: Deployment
name: time-logger
namespace: default
configMaps:
location:
name: s3-location
namespace: kanister
EOFInteracting with Amazon S3
The question now is how Kanister can communicate with Amazon Simple Storage Service (S3) (e.g., how to transfer the credentials required to access S3). Kubernetes lets you create a secret for this purpose. With Amazon Web Services (AWS) access, you need both an access key and a secret key. If you want to make these credentials accessible as a secret, you first need to Base64-encode the values, for which you can use the echo command:
echo -n "YOUR_KEY" | base64
$ cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Secret
metadata:
name: aws-creds
namespace: kanister
type: Opaque
data:
aws_access_key_id: XXXX
aws_secret_access_key: XXXX
EOFAs soon as the secret has been created in the Kubernetes cluster, you need to modify the Blueprint so that the credentials can be read from the secret and used with the aws s3 cp command. To do so, modify the command section in the Blueprint:
command:
- sh
- -c
- |
AWS_ACCESS_KEY_ID={{ .Secrets.aws.Data.aws_access_key_id |toString }}
AWS_SECRET_ACCESS_KEY={{ .Secrets.aws.Data.aws_secret_access_key | toString }}
aws s3 cp /var/log/time.log {{ .Config Maps.location.Data.path | quote }}
If you hand over the secret to the ActionSet when triggering, backing up to S3 will be successful (Listing 6).
Listing 6: Backup ActionSet
cat <<EOF | kubectl create -f -
apiVersion: cr.kanister.io/v1alpha1
kind: ActionSet
metadata:
generateName: s3backup-
namespace: kanister
spec:
actions:
- name: backup
blueprint: time-log-bp
object:
kind: Deployment
name: time-logger
namespace: default
configMaps:
location:
name: s3-location
namespace: kanister
secrets:
aws:
name: aws-creds
namespace: kanister
EOFArtifacts
The previous workflow is already capable of storing data in S3 object storage. Unfortunately, the current version totally forgets about having created an object in S3 after the ActionSet run completes. As with other pipelines, (e.g., GitLab continuous integration (CI)), Kanister also offers the option of objects persisting as artifacts so that they can be accessed again later. Artifacts are stored as key-value pairs internally and can be defined in a Blueprint. The example in Listing 7 supplements the previous Blueprint and defines an output artifact named timeLog.
Listing 7: Key-Value Artifacts
cat <<EOF | kubectl apply -f -
apiVersion: cr.kanister.io/v1alpha1
kind: Blueprint
metadata:
name: time-log-bp
namespace: kanister
actions:
backup:
configMapNames:
- location
secretNames:
- aws
outputArtifacts:
timeLog:
keyValue:
path: '{{ .ConfigMaps.location.Data.path }}/time-log/'
...After executing the ActionSet, you can also display the artifact in the status. In addition to output artifacts, you have input artifacts, which are useful for restore actions. The ActionSet in Listing 8 shows how to pass a reference to an input artifact. Do not forget to add the restore action to the Blueprint (Listing 9).
Listing 8: Passing a Reference
cat <<EOF | kubectl create -f -
apiVersion: cr.kanister.io/v1alpha1
kind: ActionSet
metadata:
...
spec:
actions:
- name: restore
blueprint: time-log-bp
object:...
secrets:...
artifacts:
timeLog:
keyValue:
path: s3://time-log-test-bucket/tutorial/time-log/time.log
EOFListing 9: Defining a Restore
restore:
secretNames:
- aws
inputArtifactNames:
- timeLog
phases:
- func: KubeExec
name: restoreFromS3
args:
namespace: "{{ .Deployment.Namespace }}"
pod: "{{ index .Deployment.Pods 0 }}"
container: test-container
command:
- sh
- -c
- |
AWS_ACCESS_KEY_ID={{ .Secrets.aws.Data.aws_access_key_id | toString }}
AWS_SECRET_ACCESS_KEY={{ .Secrets.aws.Data.aws_secret_access_key | toString }}
aws s3 cp {{ .ArtifactsIn.timeLog.KeyValue.path | quote }}/var/log/time.log
EOFAs before, the built-in KubeExec function is run and uses the current namespace, including the deployment's pod, to execute the aws s3 cp command – only in reverse this time.
Simplifying CLI Commands
Thus far, kubectl has been used to execute all the commands for Kanister, but a dedicated tool, kanctl, lets you save time by running commands on the command-line interface (CLI). The installation is quite simple:
curl https://raw.githubusercontent.com/kanisterio/kanister/master/scripts/get.sh | bashHowever, you need to install Go to use this command. After completing the installation, working with commands is far easier. For example, you can create and check an ActionSet with
kanctl create actionset --action backup --namespace kanister --blueprint time-log-bp
kubectl --namespace kanister describe actionset backup-7q23w
Or you can use the command
kanctl create actionset --action restore --from backup-9gtmp --namespace kanister
kubectl --namespace kanister describe actionset restore-backup-7q23w -4p3pc
to run a restore action.
Backing Up a PostgreSQL Database
Now that you are familiar with the basics of Kanister, you can attempt to back up a PostgreSQL database. For S3, you first need to define the bucket name in a ConfigMap and then create it in Kubernetes:
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-s3-location
data:
bucket: s3://
To create a secret, follow the same steps and store the Base64-encoded AWS credentials:
apiVersion: v1
kind: Secret
metadata:
name: aws-creds
type: Opaque
# Note: the aws keys below must be base64-encoded:
# echo -n "YOUR_KEY" | base64
data:
aws_access_key_id: <XXXX>
aws_secret_access_key: <XXXX>Most of the work is done in the Blueprint (Listing 10). The script is quite long at first glance, but, on closer inspection, you should find many familiar elements. The calls to psql, which let you encapsulate the KubeTask function, are of particular interest.
Listing 10: PostgreSQL Backup Blueprint
apiVersion: cr.kanister.io/v1alpha1
kind: Blueprint
metadata:
name: postgres-task
actions:
backup:
configMapNames:
- location
secretNames:
- aws
- postgres
outputArtifacts:
cloudObject:
keyValue:
path: '{{ .ConfigMaps.location.Data.bucket }}/backups/{{ .StatefulSet.Namespace }}/{{ .StatefulSet.Name }}/{{ toDate "2006-01-02T15:04:05.999999999Z07:00" .Time | date "2006-01-02T15-04-05" }}/pg_backup.tar'
phases:
- func: KubeTask
name: takeBackup
args:
namespace: "{{ .StatefulSet.Namespace }}"
image: ghcr.io/kanisterio/postgres-task:9.6
command:
- bash
- -o
- errexit
- -c
- |
export AWS_ACCESS_KEY_ID={{ .Secrets.aws.Data.aws_access_key_id | toString }}
export AWS_SECRET_ACCESS_KEY={{ .Secrets.aws.Data.aws_secret_access_key | toString }}
export PGHOST=${{ .StatefulSet.Name | upper | replace "-" "_" }}_SERVICE_HOST
export PGPORT=${{ .StatefulSet.Name | upper | replace "-" "_" }}_PORT_5432_TCP_PORT
export PGPASSWORD={{ .Secrets.postgres.Data.password_superuser | toString }}
pg_dumpall -U postgres -c -f backup.tar
aws s3 cp backup.tar "{{ .ConfigMaps.location.Data.bucket }}/backups/{{ .StatefulSet.Namespace }}/{{ .StatefulSet.Name }}/{{ toDate "2006-01-02T15:04:05.999999999Z07:00" .Time | date "2006-01-02T15-04-05" }}/pg_backup.tar"
restore:
secretNames:
- aws
- postgres
inputArtifactNames:
- cloudObject
phases:
- func: KubeTask
name: restoreBackup
args:
namespace: "{{ .StatefulSet.Namespace }}"
image: ghcr.io/kanisterio/postgres-task:262fc0cbc8f0
command:
- bash
- -o
- errexit
- -c
- |
export AWS_ACCESS_KEY_ID={{ .Secrets.aws.Data.aws_access_key_id | toString }}
export AWS_SECRET_ACCESS_KEY={{ .Secrets.aws.Data.aws_secret_access_key | toString }}
export PGHOST=${{ .StatefulSet.Name | upper | replace "-" "_" }}_SERVICE_HOST
export PGPORT=${{ .StatefulSet.Name | upper | replace "-" "_" }}_PORT_5432_TCP_PORT
export PGPASSWORD={{ .Secrets.postgres.Data.password_superuser | toString }}
aws s3 cp {{ .ArtifactsIn.cloudObject.KeyValue.path }} backup.tar
psql -U postgres -f backup.tar postgresConclusions
Kanister is a powerful, Kubernetes-native, open source tool that specializes in backing up data in containerized environments. With a large number of ready-to-run Blueprints for popular databases and messaging systems, it facilitates the implementation of complex backup workflows and is flexible enough to be easily adapted to individual requirements.
Infos
- Kanister: https://www.kanister.io


